
GC란? ( Garbage Collections )
18 Jun 2019 | GCGC( garbage collector )
GC란?
-
메모리 관리 기법 중의 하나로, 프로그램이 동적으로 할당됐던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기능이다. 더이상 사용할 수 없게 된 영역이란, 어떤 변수도 가리키지 않게 된 영역을 의미한다.
-
즉 짧게 설명하면 참조되지 않는 메모리 이것을 가비지로 표현합니다. 이 쓰레기 메모리들이 더이상 메모리를 점유하고 있지 않도록 해제 하는 것을 의미합니다.
GC의 역활
- GC는 메모리 내 객체를 관리하기 위해서 크게 두가지 역할을 해주고 있습니다.
- 사용되지 않는 객체 찾기
- 이러한 객체들을 메모리 상에서 정리해주기
- 그럼 GC는 어떤식으로 사용되지 않는 객체를 알수 있을까요? 기본적으로는 참조를 통해서 확인할 수 있습니다.
- 자바에서는 NEW 연산자를 통해서 객체를 생성합니다.
- GC는 언제 작동할까요? 알기 쉽게 메모리가 부족할 때 작동합니다.
User user = new User();
여기서 user는 메모리에 생성된 User을 가르키는 포인터 변수입니다. 그래서 오른쪽에 생성된 메모리 상의 대입연산자(=)을 통해서 user가 참조할 수 있도록 한것입니다. 그런데 예를 들면, 이 user ( 포인터 변수 ) 가 새로운 객체를 가르 키게 되면, 기존에 메모리에 생성되었던 User 객체는 더 이상 접근 할 방법이 없게 됩니다.
이렇게 GC는 객체와 포인터 간의 참조관계를 기록해서 이를 바탕으로 포인터 변수가 더이상 가르키지 않는 객체들을 제거하고, 그 메모리를 프로그램이 사용할 수 있도록 비워줍니다.
하지만 참조 관계만 보면 모든 쓰레기 객체들을 찾아낼 수 있을까요? 그렇지 않습니다. 리스트 자료구조의 경우, 각각의 객체들이 다음 리스트를 가리키고 있습니다.
이렇게 기차처럼 연결된 리스트의 경우에 만약 가장 맨 앞에 있는 객체를 가르키는 포인터가 다른 객체를 가르키게 되는 순간, 이 머리 객체에 연결된 객체들은 미아가 됩니다.
따라서 이러한 참조는 있으나, 프로그램에서 접근할 수 가 없으면 아무런 소용이 없기 때문에, 이러한 객체들도 관리를 해주어야 합니다.
GC는 주기적으로 메모리를 돌며 이러한 객체들을 찾아서 제거합니다.
그리고 GC중 몇몇은 객체가 있던 자리에, 덩그러니 남은 메모리 공간들을 한데모아 메모리 단편화을 해결해줍니다. 여전히 사용되고 있는 객체는 사용되고 있는 것들끼리, 그 사이사이에 남아있는 빈 메모리 공간들은 빈 공간끼리 모아서 큰 공간을 만들어줍니다.
그래서 GC는 작동방식에 따라서 4가지의 종류가 있습니다. 주로 JVM이 돌아가는 환경에 따라서 적절한 GC가 달라집니다. 이러한 일들을 처리하는 방식도 다르고, 이에 따라 성능도 달라지게 됩니다.
아무도 메모리를 건들지 않는 상황에서 GC 혼자 메모리를 모두 사용하게 되면 좋겠지만, 컴퓨터 메모리는 한시도 쉴 틈 없이 사용되고, 자바 기반의 프로그램들은 모두 멀티 쓰레드를 구현하고 있기 때문에, 수많은 메모리들을 읽고, 쓰고 있습니다.
따라서 GC가 작동하는 방식은 자바 프로그램( 쓰레드 ) 와 GC 쓰레드가 메모리를 두고 어떤 방식으로 누가 얼마나 접근할 것인지를 결정하게 됩니다.
그래서 GC가 작동할 때 기본적으로 다른 쓰레드들은 모두 메모리에 접근할 수 없도록 해주어야합니다. ( 그렇게 하지 않으면 GC가 메모리를 확보 하나 마나 소용이 없게 됩니다)
이런 GC를 제외한 모든 쓰레드가 ‘얼음’ 상태를 stop-the-world라고 합니다. 이러한 stop-the-world는 프로그램의 성능에 커다란 영향을 끼치기 때문에, 이 stop-the-world 상태를 얼마나 줄이느냐가 GC를 튜닝하는데 주된 고려사항이 됩니다.
GC의 메모리 구조 및 작동방식
- Generational GC
David ungar라는 분이 84년 ‘Generation Scavenging: A Non-disruptive High Performance Storage Reclamation Algorithm’이라는 한 논문을 발표합니다. 가설을 하나 제시하면서 Generational GC를 소개합니다. “대부분의 객체는 일찍 죽는다.” 라는 가설입니다. 실제 통계로도 생성된 객체의 98%의 객체가 곧바로 쓰레기 객체가 된다고 합니다.
이러한 경험을 바탕으로 Generational GC가 디자인됩니다. 힙을 Young Generation 영역과, Old Generation 영역으로 나눈 뒤에, Young Generation 영역을 주기적으로 청소하고, 상대적으로 오랜 기간 사용되는 객체는 Old Generation 으로 보내버리는 것이 기본 원리입니다.
이렇게 되니 GC는 매번 힙 전체를 청소하는 것이 아니라 Young 영역 위주로 청소를 하다가, Old 영역에 메모리가 부족하게 될 때만 Old 영역 청소를 하게 됩니다.
장점은 첫번째로, Young은 Old보다 사이즈가 작고 힙 공간의 일부분 이기 때문에 GC가 전체영역을 처리하는 것보다 시간이 적게 걸립니다. 즉 stop-the-world로 애플리케이션이 중지되는 시간이 짧아집니다.
두번째는 Young 영역을 한번에 모두 비우기 때문에, 이 Young 영역에 연속된 여유가 공간이 만들어집니다. 만약 GC가 군데군데 골라서 객체를 제거 했다면, 메모리 파편화 현상으로 인해서 연속된 큰 데이터가 들어갈 공간이 부족해졌을 겁니다.
그런데 Young 영역에 있던 객체들이 Old 영역으로 계속 옮겨지다 보면 언젠가 Old 영역도 가득 차게 될 건데 이때 쓸모없는 객체들을 모두 제거될겁니다.
여기서 Young 영역을 정리하는 것을 minor GC라고 하고 Old 영역을 정리하는 것을 full GC라고 합니다.
GC는 Serial, Parallel, CMS, G1 GC라는 이름으로 4가지 형태가 존재합니다.일단 GC가 Young 영역을 청소 할 때는 이 4가지 종류에 상관없이 모두 stop-the-world 상태가 발생합니다.
하지만 Old generation 영역을 청소하는 방법은 서로 다릅니다. 즉, 어떻게 다르게 청소하느냐에 따라 위에서 말한대로 4가지 종류로 구분됩니다.
- MAJOR GC와 FULL GC의 차이
Major GC 는 Tenured 영역( = Old 영역) 을 청소합니다. 그렇지만 Full GC는 Heap 메모리 전체영역을 청소합니다. ( Young and Old )
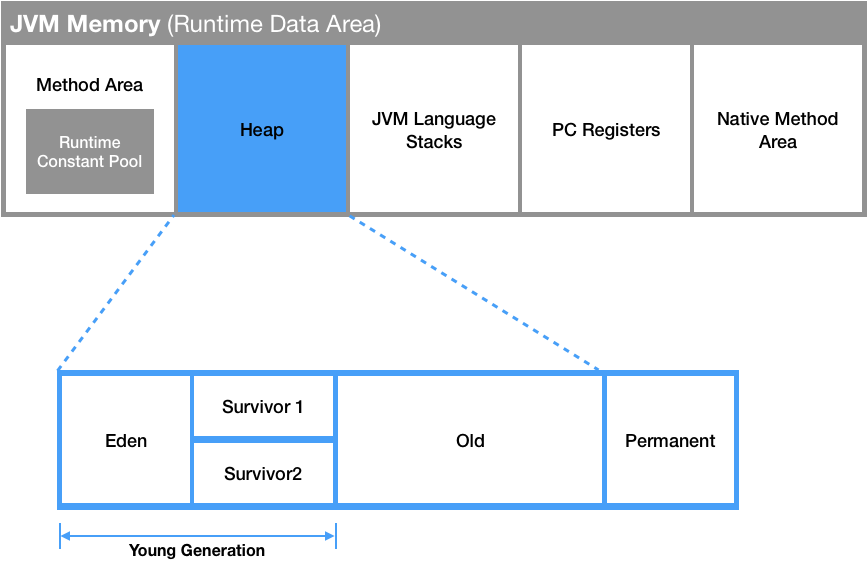
- Heap 메모리 구조
크게는 Young / Old ( Tenured ) / Permanent 영역으로 나뉘어 집니다. 그렇지만 Permanent 영역은 거의 사용되지 않는 영역이므로 실제로는 Young 영역과 Old 영역으로 나뉘어집니다. 그리고 Young 영역은 Eden 영역과 두개의 Survivor 영역으로 나뉩니다.
일단 메모리에 객체가 생성되면, Eden 영역에 객체가 지정됩니다. Eden 영역에 데이터가 어느정도 쌓이면, 이 영역에 있던 객체가 어디론가 옮겨지거나 삭제됩니다. 이 때 옮겨지는 위치가 Survivor 영역입니다.
두개의 Survivor 영역 사이에 우선 순위가 있는 것은 아니지만 이 두개의 영역중 한군데는 반드시 비어있어야 합니다. 그 비어 있는 Eden 영역에 있던 객체가 할당됩니다.
Eden에서 survivor 둘 중 하나의 영역으로 할당되고, 할당된 survivor 영역이 차면 Eden 영역에 있는 객체와 꽉찬 survivor 영역에 있는 객체가 비어 있는 survivor 영역으로 이동합니다.
그러다가 더 큰 객체가 생성되거나 더이상 Young 영역에 공간이 남지 않으면, 객체들은 Old 영역으로 이동합니다.
GC의 종류
- Serial Garbage Collector
가장 간단한 GC입니다. 주로 32비트 JVM에서 돌아가는 싱글쓰레드 어플리케이션 에서 사용됩니다. 특별히 지정하지 않을 경우 기본 GC로 지정되어 있습니다.
단순 하게 작동해서, Young 영역을 정리하는 마이너 GC때도 stop-the-world, 풀 GC할 때도 올 스탑입니다.
그리고 동작하는 GC도 싱글쓰레드로 돌아갑니다. 그렇기 때문에 데스크탑 같이 클라이언트 혼자 돌아가는 어플리케이션에서나 적합한 구조입니다.
- Parallel Collector(=Throughput Collector)
이 GC는 64비트나 JVM이나 멀티 CPU 유닉스 머신에서 기본 GC 설정이 되어있습니다. 그리고 마이너 GC와 풀 CG 모두 멀티쓰레드를 사용합니다. 위의 싱글쓰레드로 돌아가던 GC보다는 훨씬 빠릅니다. 여러쓰레드가 작동하기 때문에 이름도 Parallel 입니다. 그렇지만 마이너, 풀 CG모두 올스탑인건 Serial GC와 동일합니다.
- CMS Collector
이 GC는 풀 CG의 올스탑(stop-the-world) 상태를 줄여 볼 수 없을까? 라는 고민에서 출발한 GC입니다. Parallel GC와 동일하게 멀티쓰레드로 마이너 CG를 합니다. 그렇지만 풀 CG에서는 거의 올스탑이 발생하지 않습니다. 이유는 어플리케이션이 작동하는 와중에, 백그라운드에서 쓰레드를 만들어서 Old 영역에 쓸모없는 객체들을 찾아서 지속적으로 제거합니다.
즉, CMS의 가장 큰 장점은 풀 CG에서 올스탑이 거이 발생하지 않습니다. 단점은 백그라운드에서 지속적으로 풀 CG를 실행하니 CPU리소스를 많이 잡아먹습니다. 또한 중간 중간에 Old 영역에 쓸모 없는 객체들을 제거하기 때문에 메모리가 군데군데 비어지기 때문에 메모리 파편화가 발생하게 됩니다.
- G1 Collector
힙 영역이 매우 큰 머신을 돌리기에 적합한 GC입니다. 대신 CMS의 단점을 극복했습니다. 힙에 영역이라는 개념을 도입하고, 힙을 여러개의 Region으로 나눕니다. 몇 몇 Region은 Young 영역으로 쓰이고, 나머지 몇몇은 Old 영역으로 쓰입니다. ( 자동으로 알아서 Young과 Old를 나눠서 쓴다 )
Young 영역과 Parallel이나 CMS처럼 멀티쓰레드로 정리를 합니다. 그리고 Old 영역에 해당하는 Region이 여러개 있는데 CMS 처럼 백그라운드에서 풀 GC를 합니다. 그런데 CMS와의 차이점은 중간중간 쓸모없는 객체들을 제거하는게 아니라 통째로 한 구역을 정리합니다.
참조가 없는 객체들은 지우고, 사용중인 객체는 다른 Region으로 고스란히 복사합니다. 이로인해서 CMS에서 발생했던 메모리 파편화 현상이 발생하지 않습니다.